Overview
To download the dataset, please visit our PhysioNet page.
To learn more about the data collection study, please visit our UW-EXP study page.
Dataset Introduction
GLOBEM datasets contain the first released multi-year mobile and wearable sensing datasets that include four years of data collection studies (2018-2021), conducted at University of Washington (led by the UW-EXP Study Team).
The four years of datasets are named as
INS-W_1(2018) - 155 participantsINS-W_2(2019) - 218 participantsINS-W_3(2020) - 137 participantsINS-W_4(2021) - 195 participants
Our datasets have a high representation of females (58.9%), immigrants (24.2%), first-generations (38.2%), and people with disability (9.1%), and have a wide coverage of races, with Asian (53.9%) and White (31.9%) being dominant (Hispanic/Latino 7.4%, Black/African American 3.3%).
We envision our datasets can:
- Serve as a reliable testbed for a fair comparison between behavior modeling algorithms.
- Support multiple cross-dataset generalization tasks to evaluate an algorithm’s generalizability (e.g., different datasets across different years) and robustness (e.g., same users over multiple years).
- Assist ML and Ubicomp researchers in developing more generalizable longitudinal behavior modeling algorithms.
Data Collection and Processing
Data Collection
The overall data collection procedure is shown in the following figure:
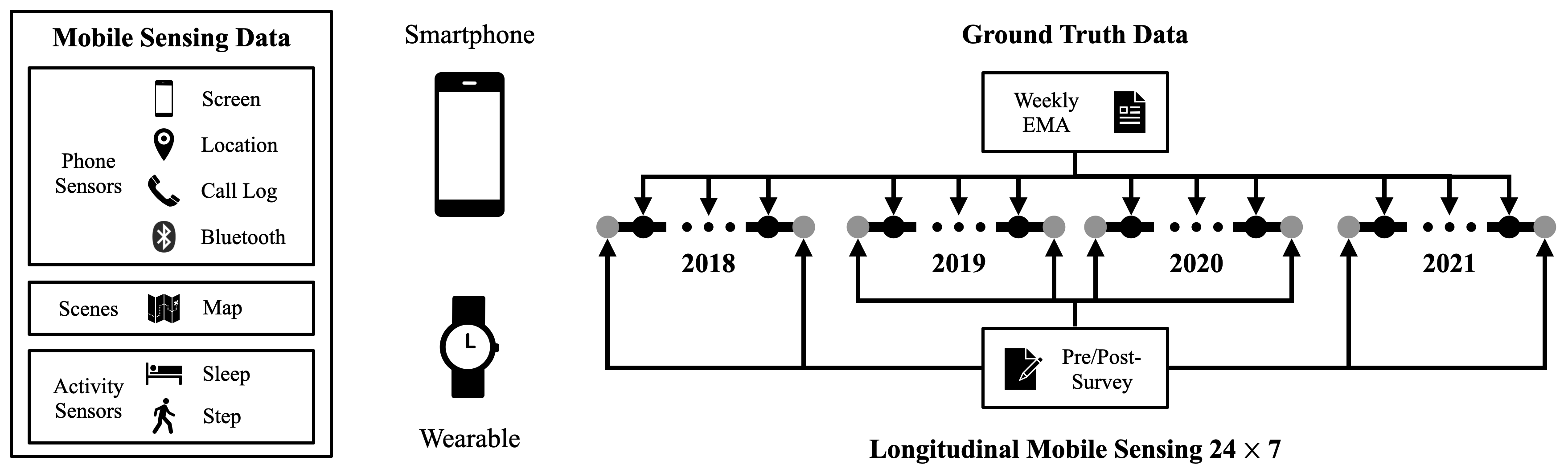
We developed a mobile app using the AWARE framework that continuously collects location, phone usage (screen status), Bluetooth scans, and call logs. The app is compatible with both the iOS and Android platforms. Participants installed the app on smartphones and left it running in the background. In addition, we provided Fitbits to collect their physical activities and sleep behaviors. The mobile app and wearable passively collected sensor data 24$\times$7 during the study. The average study length is 78 days per person per year among the four datasets.
Meanwhile, surveys are delivered to participants at the start/end and during the study. These surveys cover a wide range of life experience of participants, including personality, physical well-being, mental well-being, social justice, and substance usage.
Data Processing
Due to the sensitive nature of the dataset, we release our feature-level data with open credentialed access.
We utilize RAPIDS, an open-source platform that provides a Reproducible Analysis Pipeline for Data Streams. It supports feature extraction from data collected via multiple mobile and wearable devices with various time windows.
Data Types
Each of our datasets include three types of data: Feature Data, Survey Data, and Participant Info Data.
Survey Data
We collected survey data at multiple stages of the study, including
Pre/Post Surveys: collected at the start/end of the studyEMA Surveys: collectedly regualrly during the study
Behaivor Feature Data
Each year, our data collection study lasted three months and collected data from a mobile phone and a wearable fitness tracker 24×7. The behavior feature data types include
LocationPhoneUsageCallBluetoothPhysicalActivitySleep
Participant Info Data
We also collected additional information about participants, including the smartphone platform they installed the data collection app, as well as their demographics (e.g., age, gender, racical group)
Examples
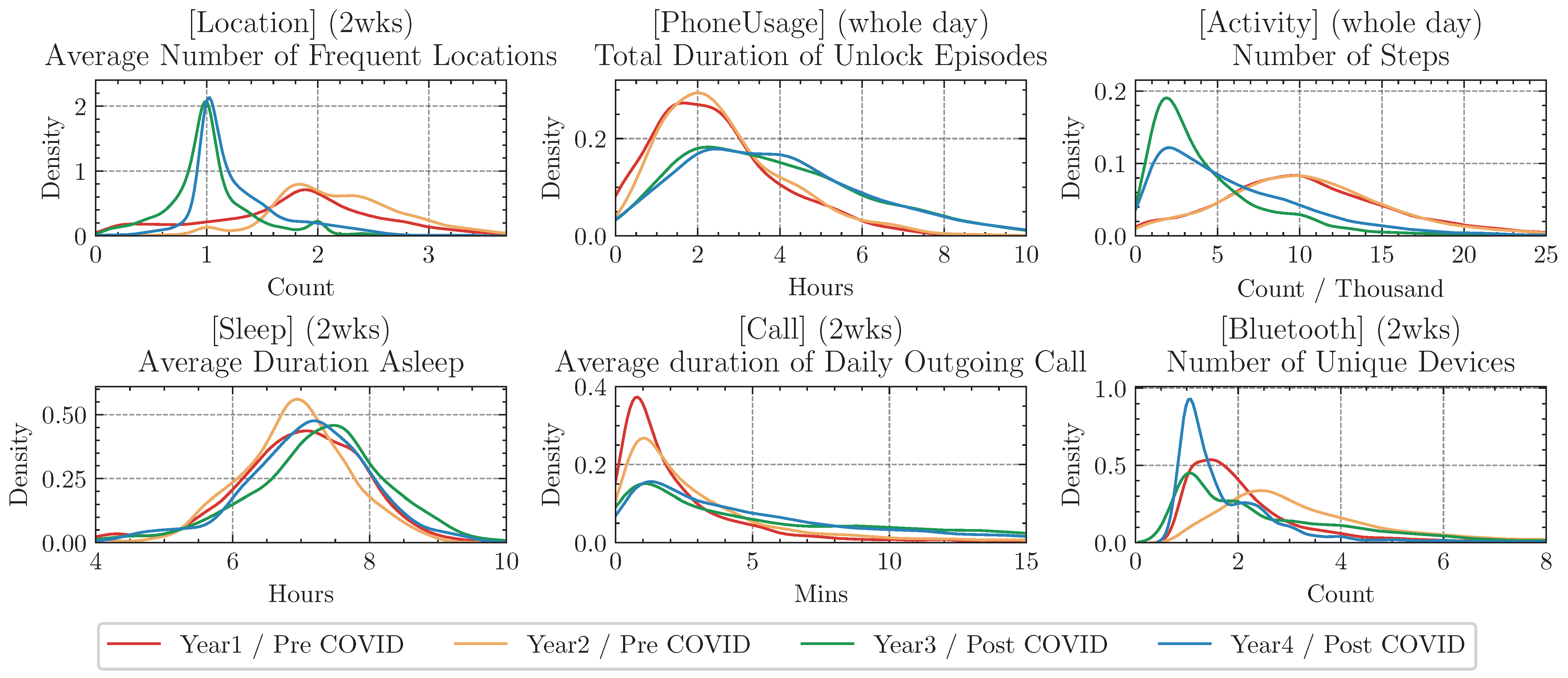
The datasets capture various aspects of participants' life experiences, such as general behavior patterns, the weekly routine cycle, the impact of COVID (Year3, 2020), and the gradual recovery after COVID (Year4, 2021).
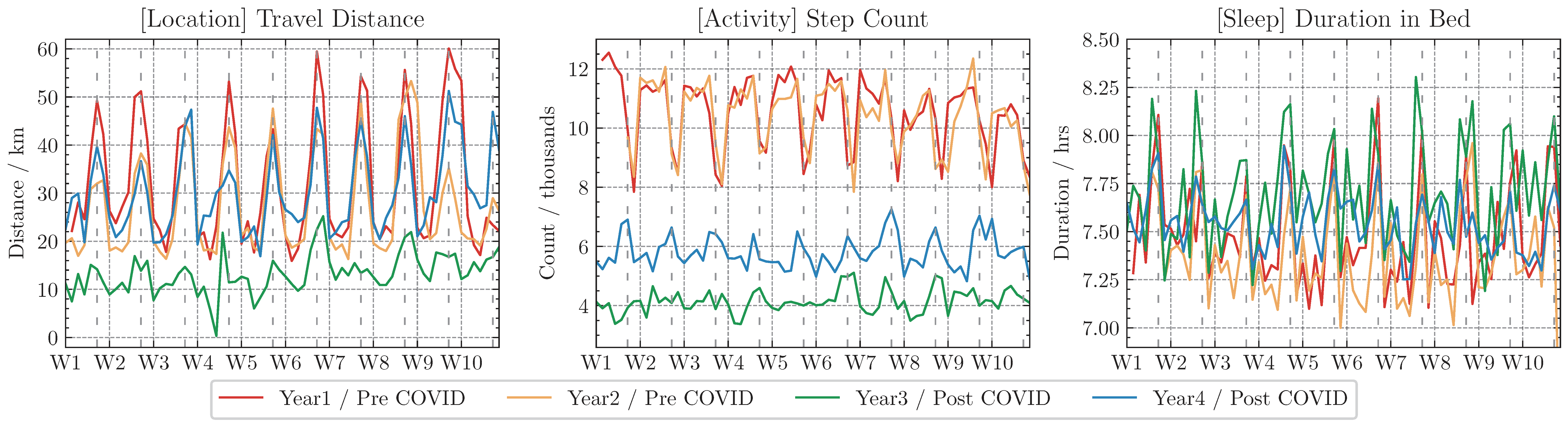
Meanwhile, each year's dataset has its uniqueness. Here we show one example from each data type.